
When people ask me something technical, I frequently find it useful to tell the basics as a story or an analogy. Obviously all these stories have limitations to how accurate they can get, but it’s surprising how well it gets people to understand what you mean. So this post is part of a series of “explaining technology as a story”
DNS
The internet basically runs on numbers (either IPv4 or IPv6). When your
desktop connects to a server, or a web site, or pretty much anything then
it uses the IP address. But humans prefer names; what is easier to
remember, www.google.com or 2607:f8b0:4004:82f::2004? DNS is
typically used to convert from the name to the number.
In a way you can think of this like a phone book. In the old days the phone company would ship you a large book (or two; “white pages” and “yellow pages”). If you wanted to phone someone and didn’t know the number then you’d look it up in the book and then dial the number. You might even have your own personal phone book with entries like “Mum and Dad”. With a modern smart phones you can search your address book for a name and the phone will be able to call them without you entering the number. This is what DNS does for the internet.
But the internet is massive; you can’t ship a “white pages” equivalent to every computer in the world. So it needs some clever lookups. So we need something similar to a telephone operator (“Goose Island, Oregon, please. The number for Dr Robert Humes”). We call these operators a “DNS Server” or “DNS Recursive resolver”.
Side note: In the early early days we did have a white pages equivalent called HOSTS.TXT. But eventually the scale of the internet made it unfeasible. It went away (much like the old phone books; I don’t think I’ve seen one for a decade!) but remnants survive in
/etc/hostsorc:\windows\system32\drivers\etc\hosts.txtand similar places.
Now these DNS servers still don’t have a complete list of every address, so they have to ask other people.
Basically the server story goes like this:
- I need to look up www.google.com. Hmm, I don’t know that.
- Let’s see. Do I know who to ask about google.com? Nope!
- OK, what about com? Can I ask someone there? I don’t no!
- Hey, “DNS root”! I know about you… can you tell me who to ask about com?
- <gets answer back; writes it in a book>
- Hey, com server? Can you tell me where google.com information can be found?
- <gets answer back; writes it in the book>
- Hey, google.com server? Can you tell me about www.google.com?
- <gets answer; also writes that in the book>
- Great! I know the answer now.
This is quite clever. It means that each operator only needs to know about things one level below it in the tree. It doesn’t need to know about everything.
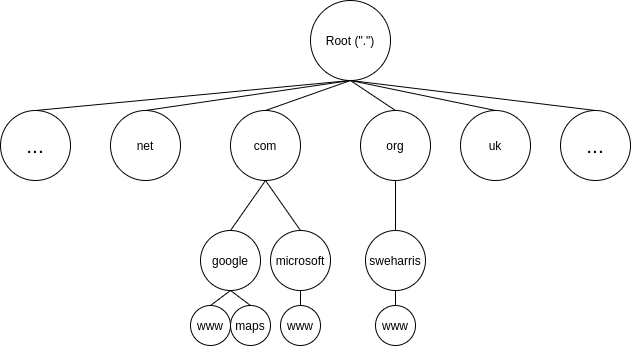
Now each time something is written in the book the server also writes down other information (e.g. when the entry was written, and how long to trust it for).
Next time someone asks the server for www.google.com it will look in the book and see “hey, I just found that out 2 minutes ago; I still trust it, and will return the same result”.
But what if someone then asks for maps.google.com? The process gets shortcutted…
- I need to look up maps.google.com. Hmm, I don’t know that.
- Let’s see. Do I know who to ask about google.com? Yes! I just looked that up a minute ago!
- Hey, google.com server? Can you tell me about maps.google.com?
- <gets answer; puts that in the book>
To make things more efficient, your local machine may also keep a small copy of the address book. So when you lookup up www.google.com it will remember it, and next time you want to go to www.google.com it will use its local copy and not even ask the operator. The web browser itself may even have an address book it keeps track of!
All these address books have to know how old the entry is and how long to trust it for. This is called the “Time To Live” (TTL). After an entry is older than the TTL then we should basically forget what we knew and ask for new data. This is how changes eventually make it across the internet so if a server moves to a new address eventually everyone should get the new data.
Summary
This story only reflects the barest basics of how DNS works (I haven’t gone into resource types, signing, delegation, glue records, and so on) and even this simplified version isn’t really accurate. There’s lots of edge cases in DNS; it’s really complicated!
But I find this story acts as a starting point.
Although I wonder how many people have even seen white/yellow pages outside of a movie? :-)