
When it comes to talking about API Security there are many facets and paths the conversation can take.
We might want to talk about from an AppDev security perspective; after all, an API is just code, so your SAST/DAST type processes apply.
We might want to talk about it in terms of authentication; after all, you need credentials to access an API and there’s many different ways this can be done (Basic Auth, mutual TLS, Oauth, HMAC…); this would also include when anonymous APIs are OK!
We might want to talk about it in encryption terms; is TLS enough or should we do payload or field level encryption?
We might…
I want to talk about it in terms of the gateway.
WAFs
Normally a WebApp needs to be behind a WAF in order to provide some protection in depth; the WAF can block abusive behaviour before it even enters your network, so common attacks (SQL injection, volumetric, buffer overflow, etc) can easily be prevents.
Side note: This doesn’t mean your app never needs worry about this; WAFs can be bypassed. This is just another layer of protection!
In a large organisation we typically find WAFs become centralised and under control of a specialist team. This adds some friction to the development process, but there’s a lot of benefits; e.g. this team has more experience in understanding attacks and can craft rules to block new ones; the WAFs can alert to the SOC; centralised logging can assist in forensics… Also it’s important to note that not all WAFs protect as well; if an app team spins up their own (eg AWS WAF, or even Apache with modsecurity) we have the management problem (how do we ensure the latest rules are deployed; how to we get visibility/alerts to the SOC; how do we even know the AppDev team deployed properly? And is this WAF providing the same level of protection that the centrally managed ones provide?).
The problem with WAFs is that they are more focused on WebApp type traffic. APIs work differently; yes, they’re still https requests and so suffer some of the same problems (SQL injection, overflow) but there’s also new challenges; e.g this is highlighted by the OWASP API Top 10 being different to the standard OWASP Top 10.
WAAP
In recognition of this, some WAF vendors have tried to introduction some level of API protection into the same product, resulting in “Web Application and API Protection” (WAAP) products. Different vendors have different levels of maturity when it comes to API Security, and few actually describe what they actually do. It can sometimes be a marketing term, just so they can tick a box on a Gartner score card.
If you already have a WAF vendor that claims they can do WAAP then definitely look at the functionality; it may be sufficient for your needs.
Security at the API Gateway
Many APIs go through a gateway, which can do some sanity checking, routing of requests to different backend systems, enforce authentication requirements, and so on. Since these gateways act as an ingress point into your application (and thus your network and environment) this is another place where it potentially makes sense to centralize.
And with a centralised API Gateway comes the ability to add security controls and make it a Policy Enforcement Point (PEP). Advanced API Gateways even have data flows that can be hooked into and process flows defined.
There’s a number of benefits to providing API Security at this layer; all the “centralised WAF” arguments apply but, in addition, we’re already doing TLS termination here so we can do inspection and enforcement without adding any noticeable additional latency to the request (an external WAF or WAAP means another TLS decrypt, resend which will add delays). AppDevs seem to care about the performance of their APIs, for some reason, so now we have the ability to add security without making them cry.
What should an API Security Gateway offer?
Inventory
Since the solution sees all the traffic (request, response) it can automatically build up a list of endpoints being called and the types of data each endpoint handles. It would be able to classify each and flag those that handle sensitive information (“Oh, this handles PCI data”, “that’s an SSN”, “Name and address seen!”).
A solution could also be able to compare this discovered inventory to the published specs (eg OpenAPI) and determine if they match or if you have endpoints that aren’t part of the published spec, or you publish endpoints that don’t actually exist.
It could also track changes in the inventory over time and alert on important changes (“Huh, this endpoint is now returning SSNs where it didn’t before”).
Another useful output would be related to the performance of each endpoint; the system has timings for how long each request/response took. This could potentially help developers detect bottlenecks (wow, a security tool helping developers? Unheard of!).
Attack detection
This is where an API Specific solution can distinguish itself from a WAF. APIs tend to be called in a pattern of behaviour; an app would call A, B, C, D in order. The solution could learn this. If it then sees traffic going A, D then we have an anomaly.
Because the solution sees traffic it could also detect when endpoints are being abused (eg if the response size goes up massively in volume, or if the number of requests to an endpoint increases; seeing authentication tokens being used from an unexpected source; excessive “fail” responses potentially indicating an enumeration attack).
Many of the OWASP API Top 10 issues can be detected just by analysing the traffic.
Of course it also should do all the standard WAF-like stuff (SQL injection, buffer overflow, bot detection, volumetric attacks etc etc).
Alerting
This should go without saying; what’s the point of having all this detection if it can’t alert the SOC, or call a SOAR, or even just log high fidelity events to a SIEM.
Blocking
Once these alerts and logs have been validated and a level of confidence in the results have been achieved then the system should be able to automatically block bad traffic.
This blocking needs to be smart, though. Blocking by IP address is kinda pointless; attackers use botnets and change source IPs on a regular basis. Blocking one IP will just result in a new one starting up a short while later. This is lesson learned from WAF management.
Instead the blocking needs to be done on patterns; is there something about the requests that can be used? Is there something about the sequence of requests that can be used?
This is likely to be biggest differentiator between products; if the vendor just says “yes, we can automatically configure the firewall to block IP addresses” then you might want to look elsewhere.
DAST
Since the system has discovered API endpoints and potentially has a Spec file, it has a lot of information that can be used to generate automated testing of the endpoints. It can call them with known bad data; test against the OWASP issues (BOLA - Broken Object Level Authorizations - being a common one).
Results of these tests could be fed into existing vulnerability management processes and so tracked to remediation.
What characteristics do we need?
Speed
I’ve already mentioned that developers will cry if we slow down their apps, so a lot of the processing for all the above should be offloaded from the gateway.
Ideally part of the “process flow” should fork off an asynchronous copy of the data and response and send it to a processing server. In this way the original data flow is barely impacted.
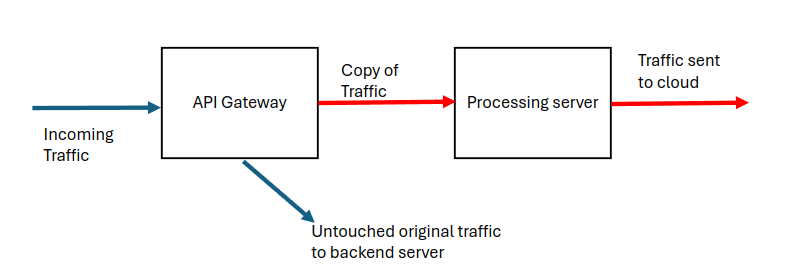
Obviously in an enterprise environment you’d have multiple servers behind a load balancer for performance and resiliency. It also makes sense to put the processing server network-close to the gateway, especially since some of the “should this be blocked” logic could be run on this server and the gateway just makes a call-out to it.
Redaction
This is important, especially if (as in the above picture) we’re sending data to the cloud. We don’t want to send PCI scoped data to the cloud (unless you want to include that as part of your CDE). This is where the processing server also helps; it can perform the analysis and then redact or hash the data before it’s sent upstream.
The upstream systems will need to have something to correlate on, so the redaction process needs to be consistent (e.g. same credit card number always get hashed to a consistent value) but the raw data itself need not be sent.
Configuration promotion
No matter how good the auto-detection of sensitive data is, the system may make mistakes (eg miss one thing, or incorrectly classify an element). The system needs to allow for custom overrides.
Now for safety the developers should be able to verify and set these overrides when developing the code or testing in QA. After all, real data shouldn’t be used here (you don’t use real data in DEV…).
Ideally we’d then want an automated way of promoting the resulting configuration and classification of fields to production before the new code gets promoted. Otherwise there’s a risk of sensitive data being exposed by mistake.
Multi-team
In a large enterprise you may have multiple development teams working on different code, potentially in totally different lines of business. And there’s no reason why the Card Issuer team should be able to see the details (or even change the classification configuration) for the Investment Banking trading APIs.
Your AppSec team has possibly already solved this issue (e.g. only allowing teams to see their own SAST/DAST results) so being able to re-use their solution (Active Directory groups… it’s nearly always AD groups!) would be nice.
API Driven
It’s all well and good having pretty UIs, but management of the platform itself needs to be automatable. We might want to automate the association of developer team to endpoints, we might want to automate updated classifications, or override blocking rules, or…
The system must be API driven, with full documentation.
Summary
There’s a lot here and it covers a lot of areas. Some parts of it impact the AppSec team (DAST, vulnerability management, code promotion, automation), other parts impact the network security team (attack detection and blocking), other parts impact the development team (seeing their inventory, allowing them to classify endpoints, performance metrics). And, of course the SOC and related teams are also impacted.
Aside: We’re going to see more of this; the “siloed” approach to security is going away as solutions cross more and more boundaries.
I feel a solution like this is going to be critical; API attacks are extremely common as more and more applications become API driven (WebApp, mobile apps, b2b tools…). The API is what exposes your data. We need a WAF-like solution!