
What is a firewall?
Think of an office building with a keycard entry system. To get into the building you need to put your card to the reader. If it think you’re authorized then the gate will open and you can enter. Similarly, a number of offices require you to “badge out” as well. This badge/gate system is a simple analogy for a firewall.
A network firewall may be considered to be a security gate to separate the network up into “inside” and “outside” and you define rules to allow traffic to pass through the gate.
The outside of a firewall is generally considered the less “trusted” environment. The inside is the more trusted. An obvious example is a firewall between your internal network and the internet. The internet is “outside” and the internal network is “inside”.
Traffic that flows from the outside to the inside is called ingress traffic. Traffic flowing in the opposite direction is called egress.
We also call the traffic that flows through a firewall to be “North-South” traffic.
Typically, in an enterprise, we control ingress traffic to restrict what an outside attacker can see. Similarly we control egress traffic to restrict what can be reached. Why would your database server even need to connect to the bitcoin network?
Internal firewalls on a network
Above I mentioned an obvious firewall location; between the internal network and the internet. However there’s also a benefit to splitting up your internal network.
A common design is the “3 tier network”.
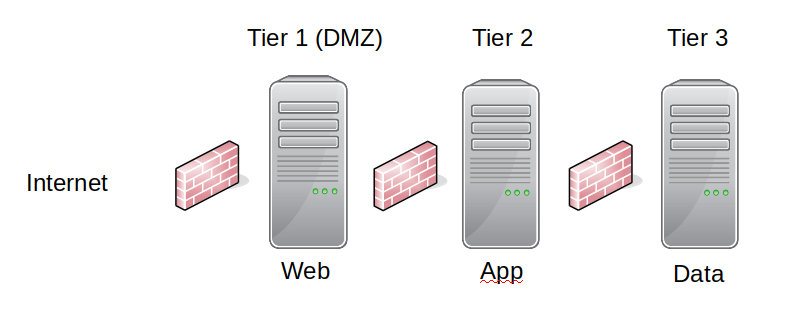
The firewall between the internet and Tier 1 is commonly called a “border firewall”. The others are “internal firewalls”.
This doesn’t look like much. What’s the advantage of all these internal firewalls?
The advantage comes in when you have multiple applications on your network (which is common to enterprises). The webserver for “application A” sitting in tier 1 (DMZ) can have permission to only talk to the application servers in tier 2 (App) that run application A. In that way if the web server is compromised it can’t even see the app servers for “application B”.
Similarly if an application server is breached (e.g. an attacker manages to jump from the web to the app tier) then the only databases they can see are those that are used by the application. Application B’s databases can’t be reached.
Now this sort of design has some limitations. “East-West” traffic (traffic between servers sitting in the same tier) isn’t restricted. This leads to a more fine grained designed, sometimes called “micro-segmentation”, but that’s beyond the scope of this blog entry!
Types of Firewall
Firewalls typically operate at 2 layers of the network stack.
IP layer
The first operates at the IP layer, and looks at packets. When a client wants to make a connection it (typically) generates a local port and then does the equivalent of “I am 10.20.30.40 port 12345 and I want to connect to 192.168.100.200 port 443”. The firewall can see this and decide whether to allow the traffic through or not.
Things get slightly more complicated because a “session” consists of multiple packets and not all of them say “I want to connect”; some of them say “and I’m part of the conversation I’m already having”. A large packet may also be split up; if you send 64K worth of data then it’s normally split up into 1500 byte or smaller fragments and then reassembled.
This leads to three types of IP firewalls:
Packet filtering
This is the original design of a firewall. Basically it would have rules that say “ingress traffic to my webserver on port 443 is allowed; the webserver can talk out”. It’s how I did Cisco ACLs back in the 90s. It works to protect against ingress traffic against unapproved services (“no, you can’t reach my ssh port!“) but some protocols may be open to abuse from an attacker sending malformed packets.
Stateful packet inspection (SPI)
This is probably the most common form of IP firewall. Now the firewall keeps track of traffic previously approved, and allows related traffic to pass through.
In my home grown router config
my iptables rules had:
iptables -A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -m conntrack --ctstate INVALID -j DROP
These use a “connection tracker” (conntrack) to keep track of traffic
and only permit relevant traffic through. Now my web server doesn’t
need to have a specific “allow to talk to the internet” rule; it can
magically respond to incoming requests. This is clearly stronger.
We also drop traffic that claims it’s related to a session, but isn’t (eg attackers sending fragments, or trying to hijack sessions with the wrong values).
Deep packet inspection (DPI)
Now we start to look inside the traffic itself and reject stuff that looks bad. At the IP layer, itself, we can block malicious traffic from hitting the web server. Both filtering and SPI are done on the headers; DPI (as the name suggests) goes deep into the packet contents. It will collect together fragments and try to understand the content of a message. Does it look bad? “Why is there HTTP traffic on the SMTP port?” Block!
In a world that is trending towards “encrypt everything”, DPI is becoming less useful. But there’s still enough unencrypted traffic that it’s not without value.
Application layer
The most common use of firewalls at the application layer are the Web Application Firewall (WAF). These are protocol specific (in this case, http traffic) and know a lot about the types of attack that can happen at that layer (“SQL injection, buffer overflow, invalid headers” for example) and can block and reject the traffic before it even hits the webserver. An enterprise with thousands of webservers may take time to patch against the latest Apache Struts vulnerability (not to pick a product at random)… but your WAF can be programmed to detect a potential attack against Struts and block it. (But still patch your servers! Don’t rely on a single defense!)
WAFs are expensive to run, both in terms of compute and in terms of operation because they are prone to false positives, but they are a critical component in a firewall posture.
For the rest of this blog I’m going to focus more on the network layer because that’s where most people run into trouble.
IPv6
At this point I should point out that IPv6 is a different protocol to IPv4. Your network firewall rules written for IPv4 will not automatically protect against IPv6 unless you have a management stack that handles both.
This has some pro’s and con’s.
For my personal home network the IPv6 rules were pretty simple; “allow access from trusted IPv6 servers; reject everything else”. But the IPv4 rules had dozens of entries to handle all the ingress rules I permitted.
For an enterprise they need to be aware that migrating from an IPv4 only environment to a (normally dual-stacked) IPv6 environment will require ensuring their firewalls also cover the new stack.
What direction?
This is where I see a lot of developers get confused. They look at traffic as to “where the data flows”. For a lot of developers “I pull data from https://api.example.com" is considered an ingress. And from a dataflow perspective it is. But from a network perspective what matters is “who initiates the connection”. If my server is making the connection then it’s an egress rule that needs to be created; “my server 10.20.30.40 needs an egress rule to talk to 192.168.100.200 on port 443”
When creating network firewall rules you need to think at layer 4 of the OSI stack (TCP, normally) and not at layer 7 (the application layer).
Is a NAT router a firewall?
No. But kinda?
NAT is nasty. It breaks a lot of rules. But, in some respects, it provides a useful ingress firewall. That’s because the machines behind the NAT gateway can’t directly be reached from the outside; they’re not routable. No one on the internet can reach 192.168.1.100. But if I add “port forward” on the router so that 443 -> 192.168.1.100:443 now the web server on that machine can be reached.
So this has some of the benefits of an ingress firewall. Nothing can be reached unless you specifically permit it! So the SPI rules kinda apply. It’s not really a firewall but kinda acts as one.
Note that has home networks start to move to IPv6 then NAT may (should!) disappear. So some of the protections home networks have had due to NAT may disappear.
Is a proxy server a firewall?
Kinda, yes?
An enterprise typically uses a proxy server to permit egress traffic to “trusted” sources. The proxy can do content inspection and reject malware and traffic to known bad hosts. In some respects we can think of the proxy as the “other side” to a WAF; WAF protects ingress traffic, a proxy protects against egress.
In a strongly controlled enterprise, firewalls should block all egress traffic by default. Only specifically opened firewall rules should be allowed. And proxies form a strong part of this. There could be a set of rules for desktops, and each server could be specifically permissioned to only see the https endpoints it’s meant to see.
Proxies have a great advantage over network layer firewalls because they work at the URL level. A web service hosted in AWS could have a gazillion of IP address and you don’t want to allow your network firewall to open all those addresses ‘cos other AWS customers also use them. But the URL? That’s easier.
I consider egress proxy rules to be far superior in these days of modern elastic compute, and so proxies form a critical component in allowing the enterprise to consume external resources.
Is a reverse proxy server a firewall?
No.
A reverse proxy, typically, just takes incoming requests from the internet and directs them to a second server. It may look at the request and forward the request to different servers; it may load balance requests. But, in essence, a reverse proxy is just a “layer 7 router”. It doesn’t add any real security and, indeed, can reduce security by exposing backend servers that wouldn’t otherwise be reachable (because the firewall has blocked it).
There are some good functional reasons to have reverse proxies in your environment (e.g. to allow the creation of unreachable networks, and have this bridge the gap) but this doesn’t replace a firewall. Indeed it’s almost an anti-firewall!
Conclusion
A firewall segregates network traffic. It may operate at different layers of the network stack. It’s a critical component for any network security model.
Understanding the underlying network layers (e.g. TCP, UDP) and the application layer is important to building a strong firewall posture.
If you’re in an enterprise and need to create a “firewall request” so your server can be reached from the internet (or reach out to the internet!) then understand the layer 4 semantics; who is initiating the connection matters more than “who sends all the data”.